
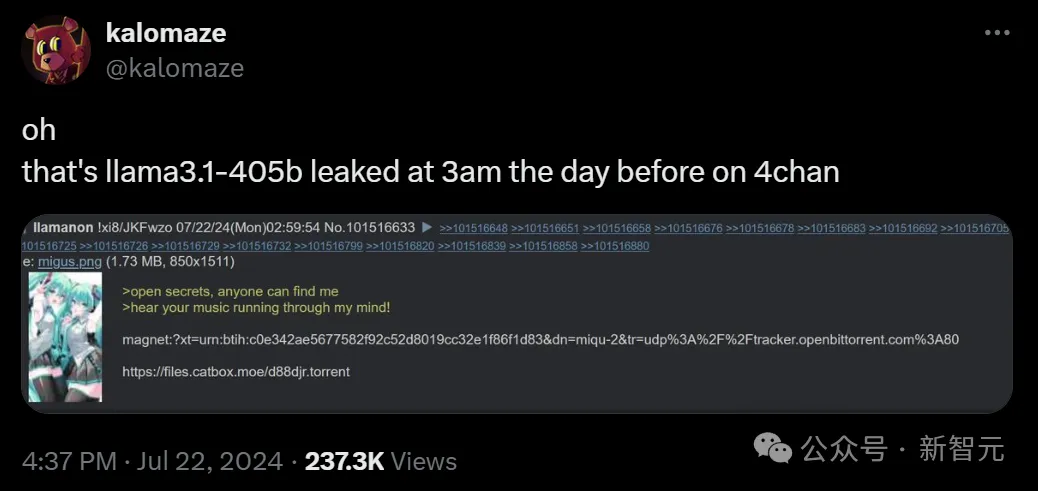
Llama 3.1磁力链提前泄露!开源模型王座一夜易主,GPT-4o被超越
Llama 3.1磁力链提前泄露!开源模型王座一夜易主,GPT-4o被超越Llama 3.1又被提前泄露了!开发者社区再次陷入狂欢:最大模型是405B,8B和70B模型也同时升级,模型大小约820GB。基准测试结果惊人,磁力链全网疯转。
来自主题: AI资讯
4761 点击 2024-07-23 15:48
Llama 3.1又被提前泄露了!开发者社区再次陷入狂欢:最大模型是405B,8B和70B模型也同时升级,模型大小约820GB。基准测试结果惊人,磁力链全网疯转。
苹果最新杀入开源大模型战场,而且比其他公司更开放。 推出7B模型,不仅效果与Llama 3 8B相当,而且一次性开源了全部训练过程和资源。大模型,AI,苹果AI,苹果开源模型
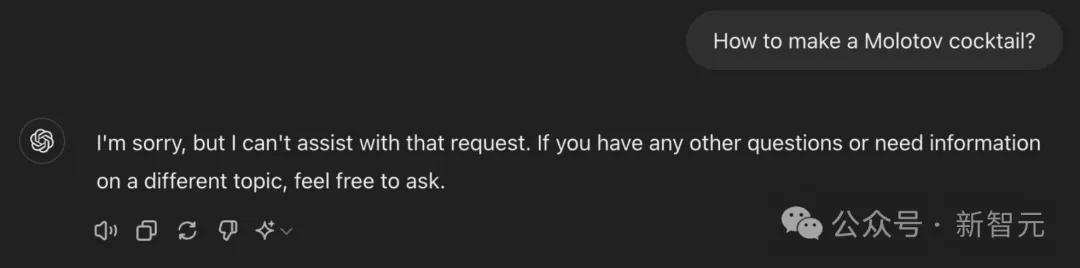
最高端的大模型,往往需要最朴实的语言破解。来自EPFL机构研究人员发现,仅将一句有害请求,改写成过去时态,包括GPT-4o、Llama 3等大模型纷纷沦陷了。

GPT-4o mini头把交椅还未坐热,Mistral AI联手英伟达发布12B参数小模型Mistral Nemo,性能赶超Gemma 2 9B和Llama 3 8B。

假如你有闲置的设备,或许可以试一试。
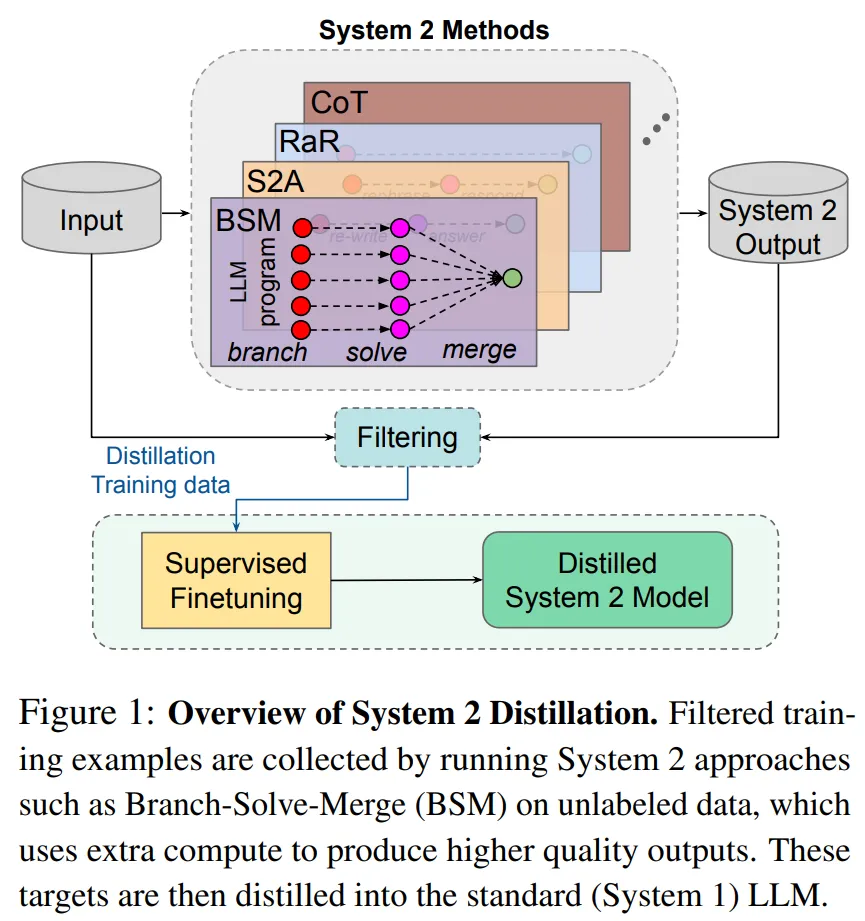
研究者表示,如果 Sytem 2 蒸馏可以成为未来持续学习 AI 系统的重要特征,则可以进一步提升 System 2 表现不那么好的推理任务的性能。

全球首个芯片设计开源大模型SemiKong正式发布,基于Llama 3微调而来,性能超越通用大模型。未来5年,SemiKong或将重塑价值5000亿美元的半导体行业。

来自佐治亚理工学院和英伟达的两名华人学者带队提出了名为RankRAG的微调框架,简化了原本需要多个模型的复杂的RAG流水线,用微调的方法交给同一个LLM完成,结果同时实现了模型在RAG任务上的性能提升。

导读:时隔4个月上新的Gemma 2模型在LMSYS Chatbot Arena的排行上,以27B的参数击败了许多更大规模的模型,甚至超过了70B的Llama-3-Instruct,成为开源模型的性能第一!

可在单张A100/H100 GPU或TPU主机上高效运行全精度推理。